How to Read Multiple Sequence Alignment Results
Multiple Sequence Alignment¶
Introduction¶
A Multiple Sequence Alignment is an alignment of more two sequences. We could align several DNA or protein sequences.

Some of the most usual uses of the multiple alignments are:
-
phylogenetic analysis
-
conserved domains
-
protein structure comparison and prediction
-
conserved regions in promoteres
The multiple sequence alignment asumes that the sequences are homologous, they descend from a mutual ancestor. The algorithms will effort to align homologous positions or regions with the same structure or role.

Multiple alignment algorithm¶
Multiple alignments are computationally much more difficult than pair-wise alignments. It would be ideal to utilize an analog of the Smith & Waterman algorithm capable of looking for optimal alignments in the diagonals of a multidimensional matrix given a scoring schema. This algorithm would had to create a multidimensional matrix with one dimension for each sequence. The retentivity and fourth dimension required for solving the problem would increase geometrically with the lenght of every sequence. Given the number of sequences usually involved no algorithm is capable of doing that. Every algorithm available reverts to a heuristic capable of solving the problem in a much faster time. The drawback is that the outcome might not be optimal.
Usually the multiple sequence algorithms assume that the sequences are similar in all its length and they conduct like global alignment algorithms. They also presume that thre are not many long insertions and delections. Thus the algorithms volition work for some sequences, but non for others.
These algorithms tin can bargain with sequences that are quite different, simply, every bit in the pair-wise example, when the sequences are very different they might have problems creating good algorithm. A good algorithm should align the homologous positions or the positions with the same structure or role.
It we are trying to marshal two homologous proteins from two species that are phylogenetically very distant nosotros might align quite easily the more conserved regions, like the conserved domains, only we volition have issues aligning the more different regions. This was also the case in the pair-wise case, simply recall that the multiple alignment algorithms are not guaranteed to requite dorsum the best possible alignment.
These algorithms are non design to align sequences that do not cover the whole region, like the reads from a sequencing project. There are other algorithms to assemble sequencing projects.
Progressive contruction algorithms¶
In Multiple Sequence Alignment it is quite common that the algorithms utilize a progressive alignment strategy. These methods are fast and let to align thousands of sequences.
Before starting the alignemnt, every bit in the pair-wise example, we take to decide which is the scoring schema that we are going to use for the matches, gaps and gap extensions. The aim of the alignment would be to get the multiple sequence alignment with the highest score possible. In the multiple alignment example we do not take whatsoever applied algorithm that guarantees that it going to go the optimal solution, just we promise that the solution volition exist close enough if the sequences comply with the restrictions assumed by the algorithm.
The idea behind the progressive construction algorithm is to build the pair-wise alignments of the more closely related sequences, that should exist easier to build, and to marshal progressively these alignments once nosotros have them. To do it nosotros demand offset to determine which are the closest sequence pairs. Ane rough and fast way of determining which are the closest sequence pairs is to marshal all the possible pairs and wait at the scores of those alignments. The pair-wise alignments with the highest scores should exist the ones betwixt the more like sequences. And so the get-go pace in the algorithm is to create all the pair-wise alignments and to create a matrix with the scores betwixt the pairs. These matrix will include the similarity relations betwixt all sequences.
Once we accept this matrix we can determine the hierarchical relation between the sequences, which are the closest pairs and how those pairs are related and so on, past creating a hierarchical clustering, a tree. We tin create these threes past using different fast algorithms like UPGMA or Neighbor joining. These trees are usually known as guide copse.
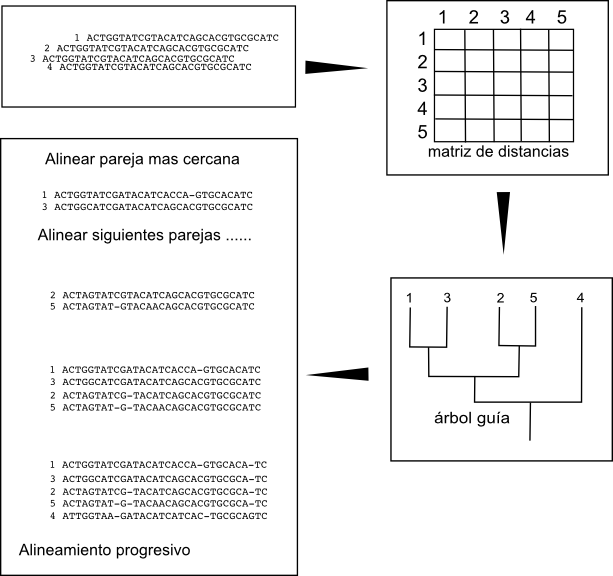
An example:
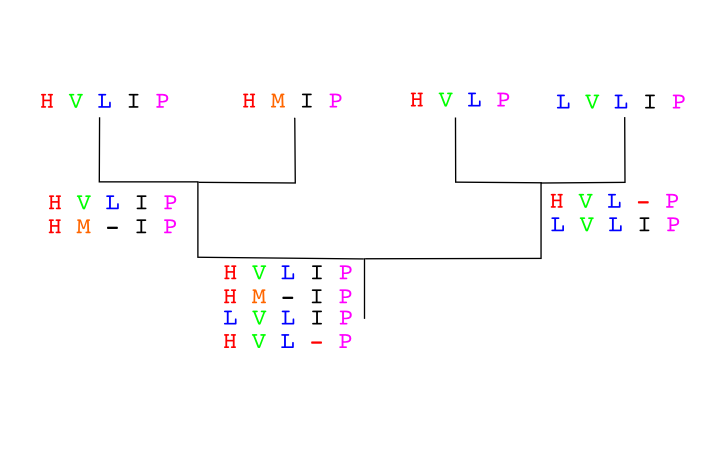
Another instance:
Secuences : IMPRESIONANTE INCUESTIONABLE IMPRESO Scores : IMPRESIONANTE X IMPRESO 7 / 13 IMPRESIONANTE X INCUESTIONABLE 10 / 14 INCUESTIONABLE X IMPRESO iv / 14 Scoring pair - wise matrix : IMPRESIONANTE INCUESTIONABLE IMPRESO IMPRESIONANTE ane 10 / 14 7 / thirteen INCUESTIONABLE ten / fourteen 1 4 / 14 IMPRESO vii / xiii 4 / 14 1 Guide Tree : |--- IMPRESIONANTE |---|--- INCUESTIONABLE | |----- IMPRESO The showtime alignment would be : IMPRESIONANTE x INCUESTIONABLE IMPRES - IONABLE INCUESTIANABLE Now we align IMPRESO to the previous alignment . IMPRES - IONANTE INCUESTIONABLE IMPRES -- O ----- We accept no guarantee that the last is the one with the highest score.
The principal problem of these progressive alignment algorithms is that the errors introduced at any point in the process are not revised in the following phases to speed up the procedure. For instance, if we introduce one gap in the start pair-wise alignment this gap will be propagated to all the following alingments. If the gap was correct that is fine, but if information technology was not optimal information technology won't be fixed. These methods are peculiarly decumbent to fail when the sequences are very different or phylogenetically afar.
Sequences to align already in the order given by a guide tree : Seq A GARFIELD THE Final Fat CAT Seq B GARFIELD THE FAST True cat Seq C GARFIELD THE VERY FAST Cat Seq D THE Fatty Cat Step one Seq A GARFIELD THE Terminal FAT True cat Seq B GARFIELD THE FAST CAT Footstep 2 Seq A GARFIELD THE LAST FA - T Cat Seq B GARFIELD THE FAST CA - T Seq C GARFIELD THE VERY FAST CAT Stride 3 Seq A GARFIELD THE Concluding FA - T CAT Seq B GARFIELD THE FAST CA - T Seq C GARFIELD THE VERY FAST True cat Seq D -------- THE ---- FA - T CAT Historically the most used of the progressive multiple alignment algorithms was CLUSTALW. Present CLUSTALW is non 1 of the recommended algorithms anymore because there are other algorithms that create better alignments like Clustal Omega or MAFFT. MAFFT was one of the best contenders in a multiple alignment software comparison.
T-Coffee is some other progressive algorithm. T-Java tries to solve the errors introduced by the progressive methods by taking into account the pair-wise alignments. First it creates a library of all the possible pair-wise alignments plus a multiple alignment using an algorithm like to the CLUSTALW 1. To this library nosotros tin add more alignments based on extra information similar the poly peptide structure or the protein domain composition. Then it creates a progressive alignment, only information technology takes into accounts all the alignments in the library that chronicle to the sequences aligned at that step to avoid errors. The T-Coffe algorithm follows the steps:
-
Create the pair-wise alignments
-
Calculate the similirity matrix
-
Create the guide tree
-
Build the multiple progressive alignment following the tree, but taking into account the information from the pair-wise alignments.
T-Java is usually better than CLUSTALW and performs well fifty-fifty with very different sequences, specially if nosotros feed it more than data, like: domains, structures or secondary structure. T-Coffee is slower than CLUSTALW and that is one of its main limitations, it can non work with more than few hundred sequences.
Iterative algorithms¶
These methods are similar to the progressive ones, but in each stride the previous alignments are reevaluated. Some of the most popular iterative methods are: Muscle and MAFFT are two popular examples of these algorithms.
Alignment evaluation¶
Once we accept created our Multiple Sequence Alignment we should bank check that the consequence is OK. We could open up the multiple alignment in a viewer to appraise the quality of the different regions of the aligment or nosotros could automate this assesment. Commonly not all the regions accept an alignment of the same quality. The more conserved regions will be more easily aligned than the more variable ones.
It is quite usual to remove the regions that are not well aligned before doing any further assay, like a phylogenetic reconstruction. We tin can remove those regions manually or nosotros tin use an especialized algorithm like trimAl.
Software for multiple alignments¶
At that place are unlike software packages that implement the described algorithms. These softwares include CLI and GUI programs as well as web services.
Ane parcel ordinarily employed is MEGA. MEGA is a multiplatform software focused on phylogenetic analyses.
Jalview and STRAP a multiple alignment editor and viewer. Another quondam software, that has been abandoned by its programmer is BioEdit.
In the EBI web server accept some services to run several algorithms like: Clustal Omega , Kalign, MAFFT, and Muscle.
Source: https://bioinf.comav.upv.es/courses/biotech3/theory/multiple.html
0 Response to "How to Read Multiple Sequence Alignment Results"
Post a Comment